Why the C-Suite needs to learn the value of data


Experts tell us that we live in a truly digital age, with data being the fuel that powers modern businesses. But data in its unprocessed (raw) form is ultimately just a series of 1s and 0s stored electronically so that computers can quickly access, process and update it.
Paradoxically, data is simultaneously worthless and priceless, and it is companies that successfully navigate between these two states that will thrive where others fail in our data-powered world.
So how do we resolve the apparent paradox between data being valueless yet enormously valuable? There’s a sleight of hand in this statement - namely that it is actionable insight that we derive from data that has value, rather than the data itself. It’s when we combine data from multiple sources, refine it, analyse it and take action guided by data that we gain real value. Information theorists call this the Data – Information – Knowledge – Understanding – Wisdom (DIKUW) hierarchy, a framework that allows us to conceptualise the increasing value associated with data as it increases in sophistication.
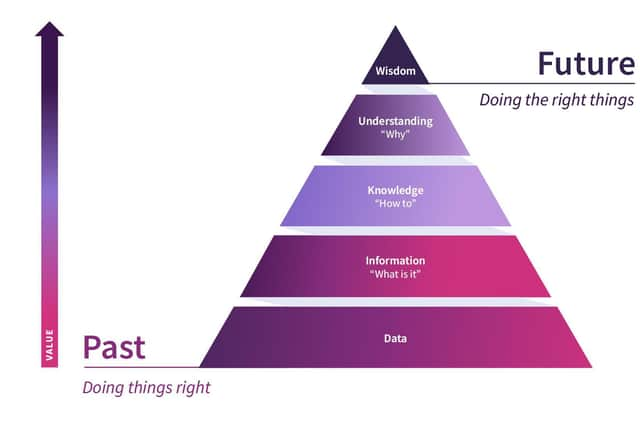
One of the key messages from this formulation is, that by providing context, refinement, augmentation and analysis to our data, we arrive at a state of Understanding, which is when we can describe and explain what has happened in the past.
Finding the true value
But what if we want to unlock even more value from our data and understand what will happen in the future? For instance, how many of our customers will take out a car loan in the next six months? How can we improve on that figure?
This is where we move into the world of Predictive Analytics, in which we use mathematical descriptions (called models) that quantify previous behaviour and, under the assumption that the same trends in behaviour seen in the past will continue into the future, we make predictions about possible outcomes.
Making predictions about the future is one of the many applications of a branch of Computer Science called Machine Learning, or ML for short. In traditional mathematical modelling, we would normally explicitly programme in the rules that govern our model. Such rules could take several forms, such as a formula and/or a series of conditional (if…then) statements. For example, in a house pricing rules-based model, we might have a rule that if the nearest school to the house in question is classed as “outstanding” then add 5% to the house value.
However, in Machine Learning we adopt a totally different approach. Instead of explicitly programmed rules, we present the computer with a sample of data, so that purposed-designed algorithms (computer “recipes”) can deduce for themselves the patterns and trends hidden within it. The algorithm then takes this “learning” from the dataset it has just seen and applies it to unseen (future) cases by way of predictions. We may well end up with a similar 5% increase in house price associated with an outstanding nearby school, but it will be the Machine Learning model that has deduced this premium, rather than a human analyst. We call the process by which the Machine Learning algorithm deduces these patterns in the data it analyses “training” and the model that comes out of training is called a “trained model”.
Machine Learning is ubiquitous. It is embedded in our mobile phones, our security systems, our music players and increasingly, our cars. Machine Learning is the way we facilitate Artificial Intelligence (AI) in which we empower computers to reason with human-like cognitive abilities. Applying Machine Learning in a structured, scientific, way forms the basis of the author’s own discipline, Data Science (DS), in which we use data-derived insight to answer one or more hypotheses and to understand what is, and isn’t possible, with the data available to us.
Using Machine Learning affords business a wealth of possibilities – from predicting the characteristics of customers most likely to default on a loan payment, to predictive healthcare. From automatic email categorisation through to automated processing of insurance claims. In a business context, the possibilities are vast, leading to efficiency gains, cost savings, competitive and innovative advantage and, ultimately, an improved bottom line.
Tread carefully
Machine Learning is not, however, a “plug and play” technology, it requires deep understanding and careful application to ensure that it is properly used.
For example, a key limitation of Machine Learning is that the model makes assumptions based upon previous behaviours. If a behaviour were to suddenly change, then the Machine Learning algorithm will, until it learns that new behaviour, continue to predict in line with the original patterns and trends it has observed. A key illustration of this would be attempting to use unmodified Machine Learning algorithms to predict purchasing behaviour across Covid event boundaries, when government lockdown policy led to significant changes in how, what and from where people purchased goods almost overnight.
Such understanding should be rudimentary for a Machine Learning practitioner. But it is often not appreciated by sponsors of Machine Learning facilities, often assuming Machine Learning to be capable of solving all their problems. Issues arise when senior sponsors struggle to understand what Machine Learning can and cannot do, and this is a fundamental piece of the data jigsaw that is often overlooked.
It is not an unreasonable position for a leader signing off the significant investment required to set up a Data Science laboratory to want to be clear on what they’ll be getting for their money and the value it will realistically bring. But where do such leaders turn to, to get the understanding they need for this? The rapid evolution of computing technology often provides a smoke screen to executives attempting to penetrate the mysteries of data-driven decisioning and accessing the right training can be problematic for them. Executive needs are very different from those of a hands-on practitioner and this is normally the intended audience for the vast majority of training courses currently in this field.
Mudano, part of Accenture, believes that effective learning needs to meet three separate requirements for it to fully embed into the learner’s long-term memory. Namely that learning must be
Understood
Practised
Relatable
In our work with executives, we address these three requirements by using a combination of strategies – structured learning, social learning and experiential learning. In other words, by using a combination of formal teaching, learning from others and learning by doing.
Events and training
Over a period of several years, we have developed a unique series of executive “Experience” events that provide an engaging, memorable and fun way for leaders to separately explore the three core areas of Data Science, Data Management, Data Engineering and, as a recent addition to the set, Data-Driven Decisioning. Each of these one-day events take senior staff on a graduated journey through their chosen topic in a safe, gamified environment where they can learn the key concepts and put them into practice in a pre-defined challenge against the clock.
We’ve had tremendous feedback from our C-level attendees who have relished the opportunity to ask all those embarrassing questions they previously never dared to, to get hands-on with the subject for real and to place what they are being told by their own experts into context. Post-event feedback has confirmed the expected return on time invested in attending the day.
Ultimately, when executives leave one of our Experience days, they are far more able to understand the art of the possible, they are refreshed after having a day away from the norm, solving a problem in a competitive, fun, environment, and they are far more confident in providing leadership to their teams as a result of their improved technical understanding.
Uncovering the missing 90 per cent
There is little doubt that we live in a world increasingly dominated by data. Estimates vary, but an oft-quoted figure suggest that globally, we are generating 2.5 quintillion bytes of data every single day – a quintillion being 1 followed by 18 zeros or 1 x 10^18. Unprocessed data in itself has limited, or no, value and it is estimated that up to 90% of corporate data is “dark” – i.e. untouched, unprocessed and unused. With such high proportions of dark data, companies are missing out on the huge potential that their data provides, and they will ultimately lose ground to those companies that do exploit their data assets to their advantage.
To reach this level of corporate data maturity requires effective, clear, leadership from the top. But herein lies a problem that is often experienced, that leaders are not confident in understanding what their data can do for them or in appreciating the benefits that technologies such as Machine Learning can bring. Training and education in this space is essential for key decision makers across the C-suite to attain the level of knowledge required to enable their organisation to do the right things with data and to successfully solve the worthless/priceless data conundrum.
Darren Seymour-Russell is Head of Data Science at Mudano, Part of Accenture Find out more at mudano.com and accenture.com/appliedintelligence